Introdução
O conceito de endianess sempre aparece em computação, principalmente quando estamos manipulando dados. Nos casos dos consoles antigos o Snes é Little Endian e o Mega Drive é Big Endian. Neste artigo explicarei esses conceitos. Assista o vídeo para ver mais detalhes e os códigos rodandos nos debuggers.
Definição de Big Endian e Little Endian
O Endianess é o termo que descreve a ordem em que uma sequência de bytes é guardada na memória. No Big Endian os bytes mais significativos aparecem primeiro, então a ordem na memória fica silimar à forma que escrevemos. No Little Endian os bytes menos significativos aparecem primeiro, portanto na memória a ordem fica invertida.
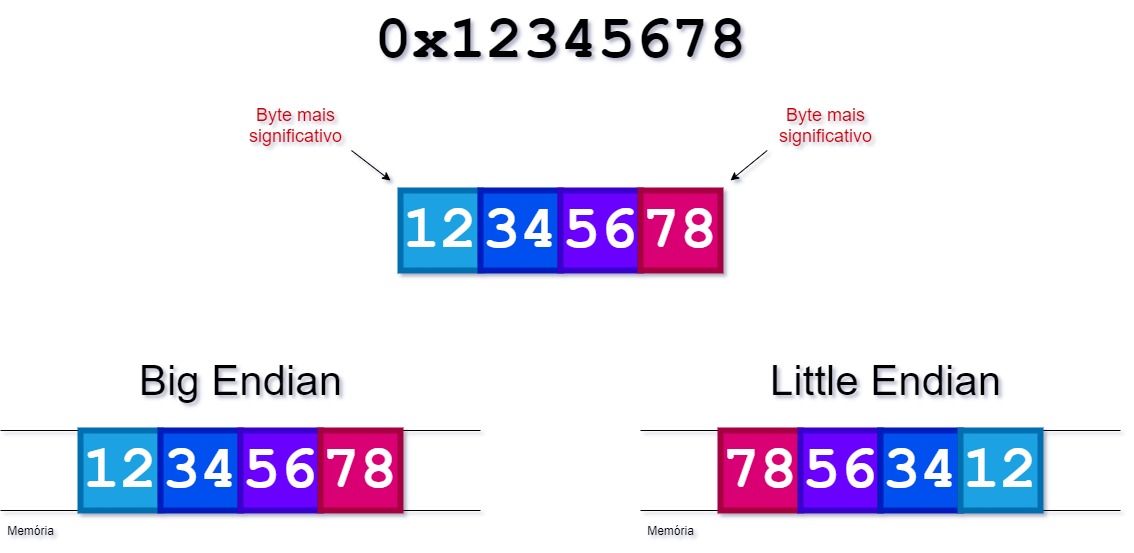
Ordem dos Bytes e dos Bits
Quandos nos referimos a Big Endian ou Little Endian, estamos considerando apenas a ordem dos bytes, e não dos bits. Portanto na quase totalidade das Cpus a ordem dos bits é sempre Big Endian, mesmo a Cpu sendo Little Endian em relação aos bytes. Então tenha em mente que um byte é um byte em qualquer Cpu, porém a partir dos bytes as Cpus se diferenciam entre Big Endian e Little Endian na ordem dos bytes.
Números, Endereços e Strings
No geral quando falamos de Big Endian e Little Endian estamos falando dos dados processados (lidos e enviados) pela Cpu. Então no geral os números e endereços tem impacto do endianess, mas Strings por exemplo já não entram nessas questões. Strings estão em um nível de abstração maior em relação à Cpu, então são considerados como um array de caracteres, e cada caractere é processado individualmente. No contexto dos consoles Snes e Mega Drive, o impacto dessas diferenças de endianess se mostram nos números e endereços que lemos e escrevemos nas memórias. Existem Cpus mais avançadas com instruções dedicadas à manipulação de strings, porém isso é outra história.
Transmissão de Dados
Também existe a questão de endianess quando o assunto é transmissão de dados. Muitos protocolos trabalham com envio de bits em transmissões seriais, então a ordem dos bits pode variar de protocolo para protocolo. No contexto dos consoles antigos existem alguns chips onde a transmissão é serial, bit por bit, então nesses casos você tem que ter esse conhecimento de endianess para saber como enviar e receber os dados de forma correta.
Network Order
Esse é um exemplo clássico de endianess que todo programador uma hora encontra. Quando enviamos coisas pela internet, é necessário se ter um padrão do formato dos dados que são transmitidos. Por exemplo, um endereço IPV4 tem 4 bytes, então a ordem em que os bits são enviados importa, pois o outro lado que recebe o dado tem que saber como decodificar a mensagem. O padrão usado pelos protocolos de rede é o Big Endian, e é o que chamamos de Network Order.
Vantagens do Big Endian
- Fica mais fácil de ler e procurar os dados na memória ou em um editor hexadecimal, pois a ordem que vemos é a mesma que escrevemos, o que ajuda muito, principalmente para quem está aprendendo.
- A transmissão bit a bit é mais natural, pois todos os bits são enviados em sequência da esquerda para a direita.
Desvantagens do Big Endian
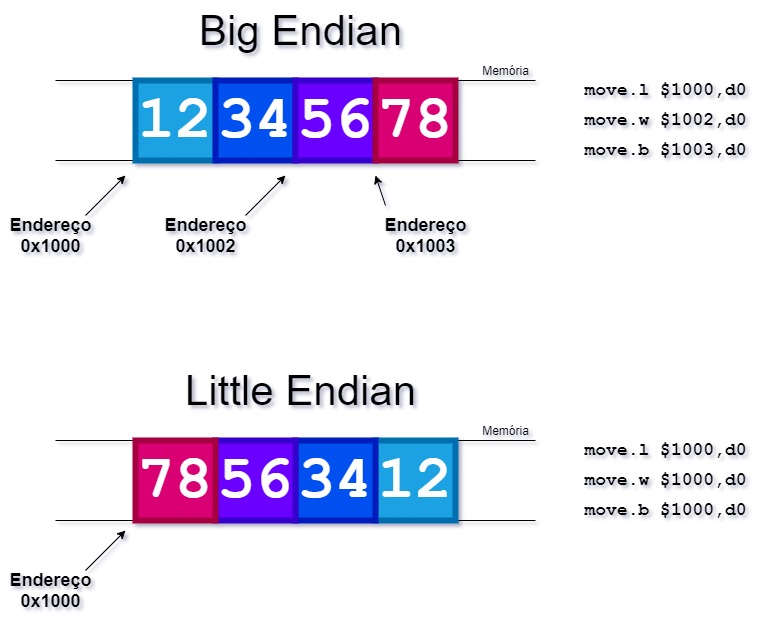
- Ao ler um pedaço de um dado maior, como por exemplo um byte ou uma word de uma long word, temos que ajustar o endereço para apontar para o pedaço desejado, o que não acontece com o Little Endian, onde sempre podemos usar o endereço do dado completo para pegar os pedaços.
- Quando fazemos uma soma multi precisão, o número resultante tem que ser expandido para a esquerda, o que nem sempre é possível e demandaria ficar empurrando os dados para a direita, o que impacta bem na performance. Com Little Endian isso não ocorre pois a expansão seria para a direita.
Vantagens do Little Endian
- Para ler um pedaço de um dado maior, como por exemplo um byte ou uma word de uma long word, podemos usar o endereço do dado completo, pois os bytes menos significativos sempre ficam na esquerda, onde começa o endereço do dado. Quando é Big Endian temos que mudar o endereço para o pedaço em questão, uma vez que os bytes menos significativos ficam na direita.
- Quando fazemos uma soma multi precisão, por exemplo, o número vai aumentando para a direita, o que é natural no Little Endian. Já no Big Endian teríamos que expandir para a esquerda, o que nem sempre é possível, o que demandaria ficar empurrando todo o bloco de dados para a direita, o que impacta bastante na performance.
Desvantagens do Little Endian
- Mais difícil de ler os dados na memória, principalmente para quem está começando, porém depois de um tempo começa a ser natural, mas não deixa de ser uma desvantagem em relação ao Big Endian.
- A transmissão bit a bit é menos natural.
Código do Mega Drive
Abaixo está o código de exemplo do Big Endian no Mega Drive. Veja o vídeo para ver os detalhes:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
arch md.cpu
endian msb //Big Endian
output "app/app.bin", create
fill $200000
macro seek(variable offset) {
origin offset
base offset
}
include "megadrive-header.asm" // Include Header & Vector Table
seek($200)
nop
nop
//Gravando long word, word e byte
move.l #$12345678,d0
move.l #$12345678,$ff0000
move.w #$1234,d1
move.w #$1234,$ff0010
move.b #$12,d2
move.b #$12,$ff0020
//Cuidado aqui!!!
move.l #$2,$ff0030
move.w $ff0030,d4
-; bra -
Código do Snes
Abaixo está o código de exemplo do Little Endian no Snes. Veja o vídeo para ver os detalhes:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
arch snes.cpu
output "snesapp.sfc/snesapp.sfc", create
fill $200000
macro seek(variable offset) {
origin ((offset & $7F0000) >> 1) | (offset & $7FFF)
base offset
}
include "snes-header.asm" // Include Header & Vector Table
seek($8000)
clc
xce
nop
rep #$30 //16 bits
//Gravando word e byte
lda #$1234
sta $0000
sep #$20 //8 bits
lda #$12
sta $0010
rep #$20 //16 bits
// Lendo uma word
lda #$0000
lda $0000
lda #$0002
sta $0020
sep #$20 //8 bits
lda $0020
rep #$20 //16 bits
// Acessando um endereço de 3 bytes
lda #$beef
sta $0050
lda #$0050
sta $0000
lda #$007e
sta $0002
lda [$00]
-
bra -